Writting down some notes when tring to understand these 2 things.
Some prerequisites
Optional:
Neural Networks Visualized Video
A blog post about LSTM
These 2 are the earlier version of AI. It describes what neural network is and how LSTM improves it.
Not directly related to Attention and Transformer.
Required:
Word embedding. But no need to go deep. Just need to know that a matrix is used to represent a word’s meaning in a vector space.
When 2 words are similar, we expect them to be close in the vector space.
Take 10 minutes to watch the word embedding section: https://www.youtube.com/watch?v=wjZofJX0v4M
Attention
I watched this Attention video: https://www.youtube.com/watch?v=eMlx5fFNoYc
To put it simple, attention is a mechanism to update the embeddings of each word(token).
The input of an attention is a series of tokens with their embeddings, which represent their meanings.
Attention will then run a process to update embeddings, so they contain rich-context information.
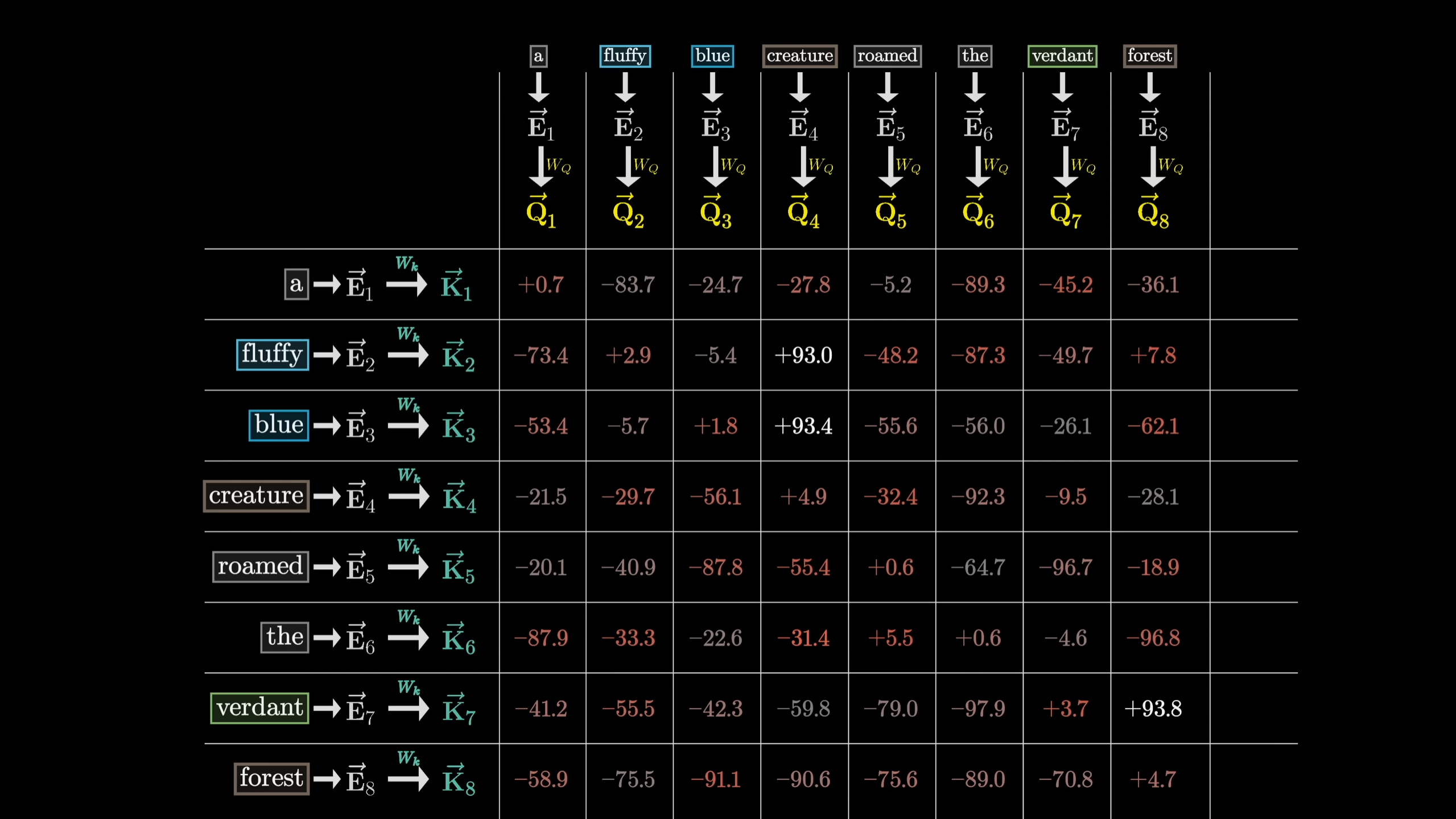
Each attention would have a few pre-trained parameters, Query Matrix (Wq), Key Matrix (Wk), Value Matrix (Wv).
When we want to udpate token xi’s embedding, the process is
- xi · Wq to generate a query Qi
- for all other xj, calculate xj · Wk to generate the Kj
- find the relevance(weight) between xj and xi by calculating the inner product of the above 2 output matrices (Qi and Kj, j != i)
- use softmax to normalize the values
- xj · Wv = Vj. sum of Vj * normalized weight (0~1) is what we add back to xi as the update
Sementic meaning
Qi (Query) → To update token xi, what information do we need from other tokens?
Kj (Key) → When other tokens ask me to evaluate how relevant I am to them, how do I respond?
xj · Wv = Vj (Value) -> When other tokens want to update themselves using my embedding, what do I give them?
Wq, Wk, Wv are pretrained parameters and are the same for updating all tokens
[screenshot from 3Blue1Brown]
This is roughly how an attention works.
Noted that the above is called self-attention (in transformer most of stuff is self-attention).
Let’s say we have 2 token sequences (a1~a3, b1~b3) with their own Wq, Wk, Wv.
If we calculate the relevance by combining Wqa and Wkb, this is cross attention.
Transformer
Input: Embedding + Positionw
Transformer layer = (Self-Attention + Feed Forward Network)× N
N layers
A Transformer layer:
3 things
1. Multi-Head Self-Attention
Each head has its own Query, Key, Value metrices
Assuming there’s 100 dimensions from the input embedding, and there’s 5 heads
The three metrices would trun the 100 dim into 20 dim
Each head would do the what attention does to a token xᵢ:
Use Wq, Wk, Wv to calculate the updated xi (20 dimensions)
Please check Attention section for details
Concate the results from different heads, then do a transformation to project it back to the original dimension (100)
2. Add & Norm
- The output from 1. + original
xᵢ - Do layer normalization (minus average, diveided by std)
To avoid the numbers going overflow. Adjust bit by bit.
3. Feed-Forward Network(FFN)
Think of it this way
- Attention:update information
- FFN: It does not act like attention taking context into consideration. Just some business logic transofrmation, independently for each token. Something like FFN(x)=W2σ(W1x+b1)+b2
🔹 4. Another Add & Norm
Stable!
Why multiple layers
Multiple layers let the model think multiple times about the same sentence.
Simple example:
The book that the student recommended is expensive.
One layer can:
-
See that “recommended” relates to “book”
-
Mix information across tokens
Two+ layers can:
-
Resolve who recommended what
-
Ignore the distracting phrase “that the student…”
-
Correctly link “is expensive” → “book”
Each layer refines the understanding.
Encoder / Decoder?
Encoder vs Decoder: can it peek on the future?
The visivbility of attention
Encoder(BERT / Embedding)
- When updating a token, use context from everywhere
- To understand
- search / RAG
Decoder(GPT)
- When updating a token, use context only before this token
- to generate next token
How to use output
GPT(Decoder-only)
- GPT updates tokens using only past context, then takes the final token’s representation. That last token goes through a linear layer and softmax to predict the next token.
BERT(Encoder-only)
- BERT updates every token by looking at the full input context, so each token encodes the complete meaning of the sentence.
- These contextualized representations are ideal for understanding tasks like classification, search, and embeddings.